

It's 2025, and time to rethink how AI is used in one of the hottest application verticals — Legal Services. Once dominated by proprietary, high-cost solutions, the field is now opening to cutting-edge general-purpose products, particularly those built with privacy and local processing at their core.
General-purpose AI tools have reached a stage where they can reliably understand and process a wide range of legal documents and scenarios. This opens the door to a new, more affordable Legal AI Stack — one we believe will increasingly include locally run, open-source AI tools that keep data off the cloud for good.
The Basics
Legal services have long been a prime target for AI applications, largely because much of the work involves processing text and images — exactly the domains where Large Language Models (LLMs) have advanced the most. Early gains, however, came at a high price: most models required expensive adaptation and post-training to handle legal documents effectively. The latest generation of LLMs, by contrast, demonstrate a strong grasp of the legal domain straight out of the box, and are increasingly being consulted by legal professionals.
In February 2025, a human baseline evaluation for Legal-Bench.PT test conducted in Portugal showed that, out of 22 professional lawyers, only four matched the performance of the highest-scoring LLM in the survey (GPT-4o). The rest generally scored on par with open-source models (such as Llama-3.1-8B). This was a notable finding, as frontier models improved substantially between February and August 2025 and now likely surpass even the top human participants. For instance, Harvey recently reported that the latest OpenAI model (GPT-5) scored 23% higher than GPT-4o on their BigLaw Bench test, and by extension, should understand legal documents at 'above-human' level.
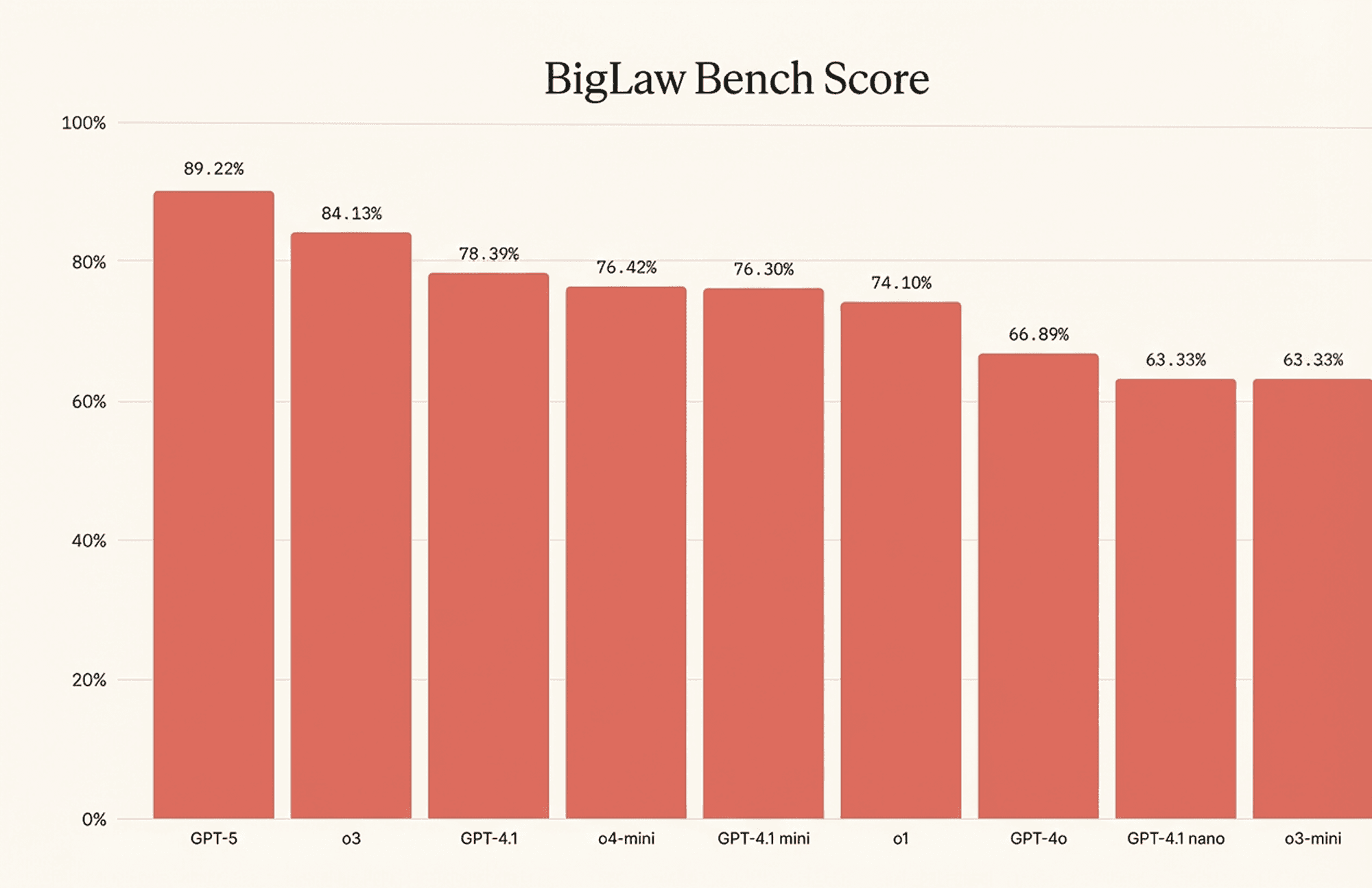
This result, quite ironically, means the proprietary Harvey AI post-training is no longer necessary, or at the very least does not hold a significant edge over just copying and pasting the legal document into a ChatGPT interface – which is something that many legal professionals already do.
Reasoning on documents, however, is not the only function defining the legal workflow. The modern law office handles a variety of tasks – some are rooted in documents, others driven by e-mails, and yet more powered by client meetings. How much of this can be improved with AI? Let's find out.
Cloud-based GPT interfaces
LLMs can be used in the legal workflow in two different forms: first, as interactive interfaces (like ChatGPT), and second – as underlying engines in applications (called via API). In most cases today, access to LLMs is cloud-based, and is subject to data processing and data handling regulations fitting the vertical – including (but not limited to) ISO 27001, SOC2, FedRAMP, HIPAA, and GDPR. Collectively, these regulation cover the possibility of unintended data leak in storage and transmission, and also discuss the possibility of using customer data for training:
Provider | ISO 27001 | SOC2 | FedRAMP | HIPAA | GDPR/DPA |
|---|---|---|---|---|---|
Yes (Cloud) | Type II | High (Vertex) | BAA (Cloud) | GDPR | |
OpenAI | - | Type II | High (Azure) | BAA (API) | DPA |
Anthropic | - | Type II | High (Azure/AWS) | BAA | DPA |
Perplexity | 27001:2022 | Type II | - | Yes (Enterprise) | DPA/GDPR |
Pragmatically, using a GPT app from a top-tier provider for legal purposes is likely okay, but with one important caveat: it must be configured for training opt-out. This is because most web-based consumer apps for LLMs by default permit training (regardless of access tier).
E-mail and calendar AI connectors
Artificial Intelligence is a powerful general-purpose tool, but a copy-and-paste approach only gets you so far. In real-world legal practice, an attorney or paralegal must respond to client and opposing counsel emails, manage court and client calendars, retrieve documents from prior matters, and synthesize notes from depositions and meetings. An AI agent capable of securely searching across these sources, understanding their context, and taking appropriate actions can significantly reduce administrative overhead—freeing legal professionals to focus on substantive case strategy and client advocacy.
This need drives a case for granting AI tools privileges to access the data sources directly. For example, Perplexity can be configured with a Gmail connector that would allow AI to perform agentic actions like reading select emails and drafting specific responses. Likewise, a meeting scheduling agent can be configured to answer e-mail requests by managing user's calendar.
In general, these automations are useful and in many cases can supplement (or replace) the need for heavier, all-around AI toolkits like Thomson Reuters' CoCounsel.
One poorly understood aspect of these tools, however, is how exactly they handle the data permissions. In a nutshell, if a legal professional is granting a third-party access to calendar scheduling, this also exposes the entire list of current, future, and past appointments – in addition to any and all associated attachments. For example, forwarding an e-mail from a customer to scheduler agent with instructions to 'schedule a meeting' coincidentally grants the (most likely unwanted) access to the entire e-mail thread which might contain sensitive information.
Similarly, blanket access rights to the mailbox are equivalent for ceding permissions to read, write, and send any data to anyone – including 3rd parties not on the contact list for this mailbox. This makes the consequences of rogue AI agent behavior especially dire – one misinterpreted instruction may cost a customer or an entire career to someone too reliant on artificial intelligence.
The transparency and compliance parts of the connector experience are also of a particular interest. Very often, the makers of AI connectors (e.g. Gmail plug-ins) do not disclose the full capabilities of their product, and offer no ways to guardrail it. Moreover, even if an AI vendor (for instance Perplexity), has their AI chat interface covered under compliance rules, they do not automatically extend to connectors and actions executed over those connectors.
The Power of Local AI
If we classify the modes of failures of artificial intelligence in legal workflows, it will be easy to notice they generally fall into one of three categories:
Low performance / hallucination: The AI did receive proper instructions but produced the output not up to expected standards.
Violation of access privileges / tool use / guardrails: The AI reached into data or capabilities not intended for it to use. This could happen due to unclear instructions, human error, or excessively wide permissions granted to an agent.
Data leakage / sharing outside the intended organization: This mode of failure occurs when sensitive data appears in wrong custody (provider storage, hackers, or training dataset) as part of the normal cloud AI processing.
The first failure mode is the easiest one to imagine, but also is a progressively smaller threat as AI models mature. Many legal professionals today use AI for preliminary document understanding, and are usually able to prevent errors of this sort by cross-checking results against humans, or different AI models.
The second failure mode is complicated and required granular access policies and privileges. We will dedicate a separate post to this vast and interesting topic.
The third failure mode, however, has a potential for an easy fix in those cases where legal professionals can constrain AI execution to their own devices and use the local AI capabilities.
Until recently, local AI was not very powerful and could not compete with bleeding edge of commercial cloud-based offerings. This has changed late 2024 and into 2025, when a slew of very powerful open-weight models became available for the higher end of consumer hardware (from Apple, Nvidia, and Intel to name a few). Specifically, a recent MacBook with 36GB unified memory can run OpenAI's gpt-oss-20b model (good enough for most service work), and a MacBook with 64GB memory can operate gpt-oss-120b model with intelligence comparable to flagship o4-mini.
Perhaps even more importantly, there are already consumer-grade products which integrate these models at low cost (or for free) for AI processing that does not leave the user's machine.
Here is an (incomplete) list of the local AI processors which solve the problem of data leakage in legal office without breaking the bank:
Ollama
Ollama excels at smooth installation of local AI models on consumer-grade hardware and can function as a drop-in replacement for desktop versions of OpenAI and Antropic chat interfaces. The latest OSS models from OpenAI also support web search capability.
We recommend any legal office working on sensitive information to take a look at Ollama and think of ways to integrate it into handling the cases with high cost of unintentional data leakage.
Hyprnote
Hyprnote replicates a popular Granola AI meeting notetaker in a locally run package – no audio, text, or summaries of your meetings ever leave your laptop. When taking and organizing meeting notes, Hyprnote is a no-brainer as everything stays local.
Minima
Unlike Ollama and Hyprnote which are packaged as consumer apps and will work right out of the box, Minima is a devtool and requires some software knowledge to set up. The return on investment for Minima is the ability to automatically complement your AI chats in Anthropic Claude Desktop and other AI platforms supporting MCP with search and references over your private data – including text, PDF, and image files of prior cases.
Conclusions
Advances in AI models are quickly democratizing access to artificial intelligence for legal professionals without access to large, integrated AI platforms. It would be reasonable to say that a large part of legal workflow today can be offloaded to general models that lack specific legal training.
This said, privacy, confidentiality, and control of AI behaviors remain large concerns and must be mitigated before embracing AI in every part of the legal process. In doing so, we advocate considering the growing toolkit for local AI data processing.
